浅读Few-Shot Adaptive Faster R-CNN
[TOC]
前言
- 说明:
- 为了通过阅读论文来提升自己的科研水平,记录下paper作者的大体work、阅读论文收获的点以及产生的新想法。
- 本文阅读的paper为CVPR2019-Few-Shot Adaptive Faster R-CNN。
- 本文主要从paper研究的问题、paper通过何种方法来解决该问题、paper给出的效果和理论依据这三个方面来进行展开。
概述及论文背景分析
综述:
- 这篇论文是为了减轻由于域移位而导致的检测性能下降的负效应。
- 原有大多数域自适应方法由于目标域数据不足、对象检测模型复杂、存在过适应和不稳定现象而无效。
- 为了缓解目标域样本不足的问题,在源特征和目标特征上引入了一种配对机制。
- 提出了一个双层模块使源数据的训练检测器适应目标域。
-
双层模块包括:
-
基于拆分池的图像水平自适应模块,均匀地提取并对齐位置上成对的局部补丁特征,并保持不同的纵横比例。
-
实例级适配模块,在语义上对齐配对的对象特征,避免了类间的混淆。
-
同时,采用源模型特征正则化(SMFR)来稳定两个模块的自适应过程。
-
背景分析:
主要是对R-CNN、Fast R-CNN、Faster R-CNN做一个补充说明。传统的目标检测方法都是区域选择、特征提取、分类回归三步流程。带来的有时间复杂度高、区域选择策略效果差、手工提取的特征鲁棒性差等问题。而深度学习介入后R-CNN就在目标检测中占据了很大地位。到现在,R-CNN已经是一个比较大的集群了,其下有SPP Net、Fast R-CNN、Faster R-CNN、Mask R-CNN等子属。
R-CNN:区域卷积神经网络
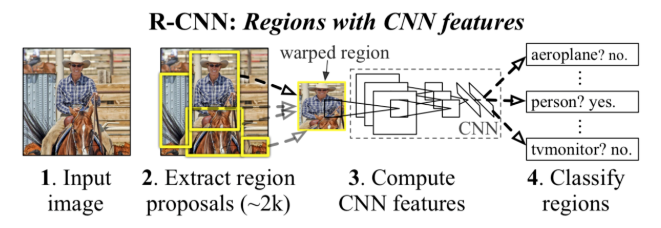
- 流程:
- 选取一个预训练卷积神经网络CNN。
- 根据需要检测的目标类别数量,训练CNN的最后一层。
- 将源图片作为输入。
- 用选择性搜索得到感兴趣区域(~2k个):
- 对区域重新改造,让其符合CNN的输入size要求,将这些区域输入到CNN中,并经过卷积网络。
- 对每个类别,都训练一个二元SVM,CNN为每个区域提取特征,利用SVM将这些区域分成不同类别。
- 训练一个线性回归模型,为每个辨识到的物体生成更精确的边界框。
- 缺点:
运用R-CNN进行目标检测,要根据选择性搜索提取每张图片的2K个单独区域,固所提取的特征多,且R-CNN还需要用到线性SVM分类器以及调整边框界的回归模型,使得R-CNN处理速度慢,无法处理大型数据集。
Fast R-CNN:快速区域卷积神经网络
Q:简单地来说,Fast R-CNN就是比原先R-CNN的处理更快了。那么Fast R-CNN是如何做到的呢?
A:可以减少对源图片做CNN的次数。在Fast R-CNN中,将图片输入到CNN后,会相应地生成传统特征映射。利用这些映射,就能提取出感兴趣区域。再使用一个Rol池化层就能将所有提出的区域重新修正到合适的尺寸,输入到完全连接的网络中。
- 流程:
- 将源图片输入到一个基础卷积网络,得到整张图的感兴趣区域。
- 然后用一个RoI(Regions Of Interest)池化层,保证每个区域尺寸相同,为region proposal从感兴趣区域中提取固定长度的特征向量。
- 再将特征向量传递到一个完全连接的网络中进行分类,并用softmax和线性回归层同时返回边界框。
- 缺点:
在处理大型数据集上,速度仍不够快。
Faster R-CNN:更快了,采用了RPN(Region Proposal Networks)
使用RPN产生的proposals比选择性搜索要少很多(300vs2000),因此也一定程度上减少了检测的计算量。
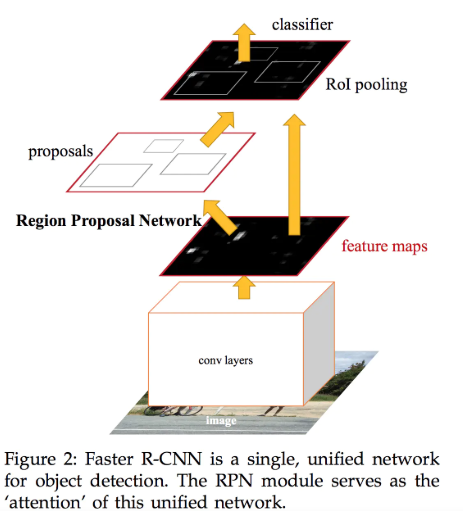
- 流程:
- Conv layers:使用一组基础的conv+relu+pooling层提取image的feature maps。该feature maps被共享用于后续RPN层和全连接层。
- Region Proposal Networks:RPN网络用于生成region proposals。该层通过softmax判断anchors属于foreground或者background,再利用bounding box regression修正anchors获得精确的proposals。
- Roi Pooling:该层收集输入的feature maps和proposals,综合这些信息后提取proposal feature maps,送入后续全连接层判定目标类别。
- Classification:利用proposal feature maps计算proposal的类别,同时再次bounding box regression获得检测框最终的精确位置。
注:细则以及实现代码本节内容不作过多赘述。
内容解析
介绍
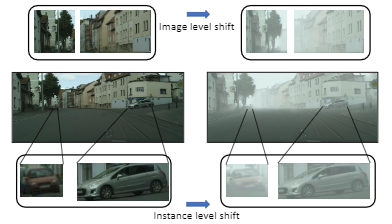
- 中排左右分别显示了正常情况下和带雾情况下的城市景观,顶行显示反映图像级别域映射的背景补丁,底行显示反映对象实例级别域映射的独立对象(汽车)。
-
上图显示,有限的目标样本仍可以在很大程度上反映主要领域特征,例如光照,天气状况,单个物体的外观。
- 解决深层CNN模型的域映射问题主要针对非监督域适应(UDA)设置。本文探讨了仅带有一些松散注释的目标图像样本,使用源域数据训练适应到目标域的对象检测器(并非所有对象实例都被注释)的可能性。
建立的FAFRCNN模型具有以下优点:
- 快速适应性:仅需要数百步适应更新,对比原始方法需要训练数万个步骤。
- 数据收集成本较低:仅具有代表性的数据样本很少,FAFRCNN模型可以大大提高目标域上的源检测器。可以大大减少人工注释时间
- 训练稳定性:能够避免由于有限目标数据样本造成的过度拟合,并受益于少数目标样本。
相关工作
简单地提了一下目标检测、跨域对象检测、少样本学习。
实现方法
- 这里将详细介绍paper提出的少样本域映射自适应检测方法。
问题设定
假设有大量的源域训练数据集(XS,YS)和少量的目标数据集(XT,YT),其中XS和XT是输入图像,YS表示XS的完全边界框注释,而YT表示XT的松散注释。在目标域图像中仅注释了几个对象实例的情况下,目标是使在源训练数据上训练的检测模型适应目标域,同时性能下降最小。 在此仅考虑宽松的边界框注释以减少注释工作。
图像级别的适应
- 补丁特征提取
使用分割池(SP)来均匀提取具有不同纵横比和比例的位置之间的局部特征补丁,以进行领域对抗。在给定网格宽度w和高度h的情况下,拆分池首先在x轴和y轴上生成从0到整个网格宽度的随机偏移量Sx和Sy,分别为( 即,0 <sx <w,0 <sy <h,sx,sy∈N)
如图2左上方所示。
- 对抗性自适应Faster R-CNN模型(FAFRCNN)的框架
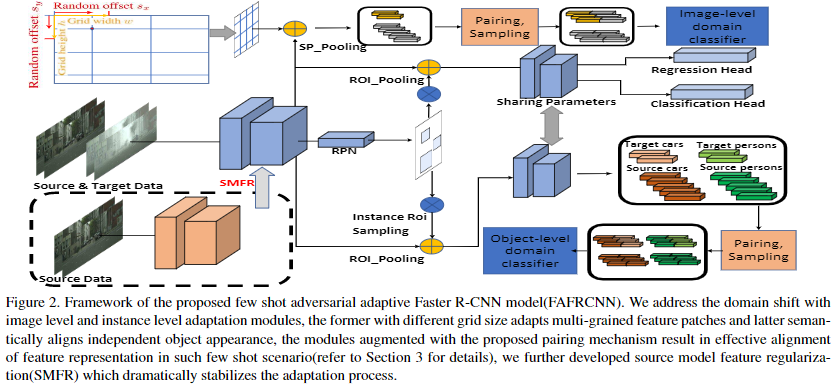
- 网格选择
在Faster R-CNN中,已将网格窗口的宽度和高度设置为比例和比例作为锚框。 根据经验选择3个比例尺(大比例尺256,中比例尺160和小比例尺96,对应于VGG16网络的relu53上的特征尺寸16、10和6)和3个纵横比(0.5、1、2),得出9 对。 对于每一对,都会生成网格,然后使用ROI池将网格中的非边界矩形合并为固定大小的要素。 通过合并,可以使不同大小的网格与单域分类器兼容,而无需更改提取特征的逐块特征。 正式地,将其作为特征提取器,并将X作为输入图像集。 Weperform拆分池分为三个级别,分别作用特征spl(f(x)),spm(f(x))和sps(f(x))。
- 局部配对特征多尺度对齐
将从分割池中提取的局部特征配对成三个比例尺中的每个比例尺来解决图像级偏移,例如,对于小规模块,Gs1 = {(gs,gs)},Gs2 = { (gs,gt)},其中gs〜sps(f(XS))和gt〜sps(f(XT))。 在这里,第一组Gs1内的对仅由源域中的样本组成,第二组Gs2中的对由源域中的一个样本和目标域中的另一个组成。
- 领域对抗学习目标
使用鉴别器清楚地区分源特征对与目标特征对。以小规模鉴别器D^sps的目标学习来最小化:
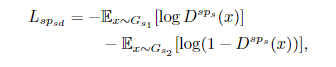
同理,图像级别的鉴别目标是最小化:
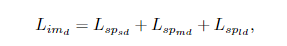
而特征生成器就是最大化Limd。
实例级别的适应
- 实现方法
将Faster R-CNN ROI采样扩展到实例ROI采样。以Faster R-CNN ROI采样方案对ROI进行采样,来创建分类和回归头的训练数据。
- 实现参数及公式选择
实例ROI采样使所有前景ROI都具有较高的IOU阈值(实现中为0.7),以确保ROI更加接近实际对象区域并适合对齐。 根据源和目标域图像的类,将其前景ROI特征通过中间层(即,在ROI合并之后但在分类和回归头之前的层)传递,以获取源对象特征Ois和目标对象特征Oit的集合。 这里,∈[0,C]是类别标签,C是类别总数。 然后将它们进一步以与图像级补丁特征相同的方式配对为两组,从而导致Ni1 = {(nis,nis)}和Ni2 = {(nis,nit)}。
- 鉴别器处理
实例鉴别器目标最小化:
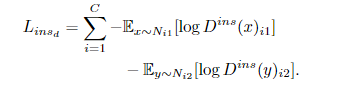
特征生成器的目标最小化:
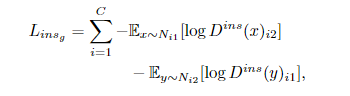
这里的D^ins(x)表示第一/二组第i类上的鉴别器输出。
原模型特征正则化(SMFR)
- 解决过度拟合不稳定具体做法
强制适应的模型对源输入产生与源模型相同的特征响应,即L2差异。避免将学习的过度更新表示为有限的目标样本,从而降低性能。
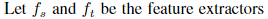
以上分别为源模型和适应模型的特征提取器。正则公式为:
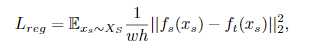
将正则化强加给全局特征图会在适应目标域时导致严重恶化。 因此,将特征图上的那些前景区域估计为锚点位置,这些锚点的IOU的地面真实度框大于阈值(在实现中使用0.5)。 表示估计的前景蒙版。 然后修改原先的正则化如下:
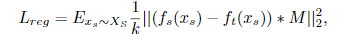
FAFRCNN的模型训练
FAFRCNN的训练使用源模型初始化框架,并通过在以下目标之间进行交替来优化该框架:
- 步骤1:最大程度地减少以下完全检测模型损失
- Lg =α(Limg + Linsg)+βLdet+λLreg,其中,Ldet表示对源数据进行更快的R-CNN检测训练损失,α,β和λ是控制损失之间相互作用的平衡超参数。
- 步骤2:最小化跟踪损失。 域标识符:Ld = Limd + Linsd。
实验
提出了针对采用多种数据集构建的不同域移位的适应方案提出的方法的评估结果。 在实验中,检测模型为基于VGG16网络的Faster-RCNN。
数据集和设置
数据集
- SIM10K 数据集,包含10k合成图像,带有针对汽车,摩托车和人的边界框注释。
- Cityscapes数据集,包含约5000个带有像素级类别标签的准确注释的真实世界图像。
- 有雾城市景观数据集,是从具有模拟雾的城市景观中生成的。
- Udacity自驾车数据集,是一个开源数据集,它以不同的照度,相机条件和周围环境作为城市景观来收集。
以上数据集都在paper文献引用上有注明。
评估情景
- 情景1:SIM10K到Udacity(S→U)
- 情景2:SIM10K到Cityscapes(S→C)
- 情景3:从Cityscapes到Udacity(C→U)
- 情景4:Udacity到Cityscapes(U→C)
- 情景5:从Cityscapes到 Foggy Cityscapes(C→F)
对照组(baseline)
- 源训练模型。 该模型仅使用源数据进行训练,并直接在目标域数据上进行评估。
- ADDA ,是处理无监督对抗域适应的通用框架。
- 域传输和微调(DT + FT),该方法用于使目标检测器适应目标检测器。 在UDA设置中,使用CycleGAN 训练源图像并将其转换为目标域。 在FDA设置中,由于几乎没有可用的目标域样本,因此采用的方法(引用文献)仅需要一个目标样式图像即可训练转换。
- 域自适应Faster R-CNN ,该方法是专门为无监督域自适应开发的,表示为FRCNN_UDA。
定量结果
- 情景1和情景2

就汽车检测的平均精度而言,在方案1和方案2中的方法的定量结果显示如上。 UDA表示传统环境,在该环境中可以使用大量未标记的目标图像,而FDA表示少数镜头域适应环境。 sps,spm,spl分别表示小型,中型和大型拆分池。 “ ins”表示对象实例级别适应,“ ft”表示使用可用的目标域注释添加微调损耗。 对于FDA设置,S→U和S→C均在每个实验回合中采样8个图像,并为每个图像标注3个汽车对象
- 情景3和情景4

对于FDA设置,C→U每轮实验采样16幅图像,U→C每轮采样8幅图像,每幅图像都标注3个汽车物体,其余一致。
- 情景5
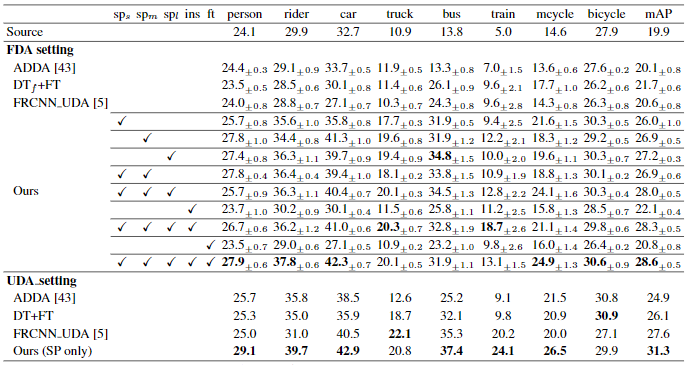
每个实验回合采样8张图像(每类1张图像),并为每张图像的相应类标注1个对象边界框。
定性结果
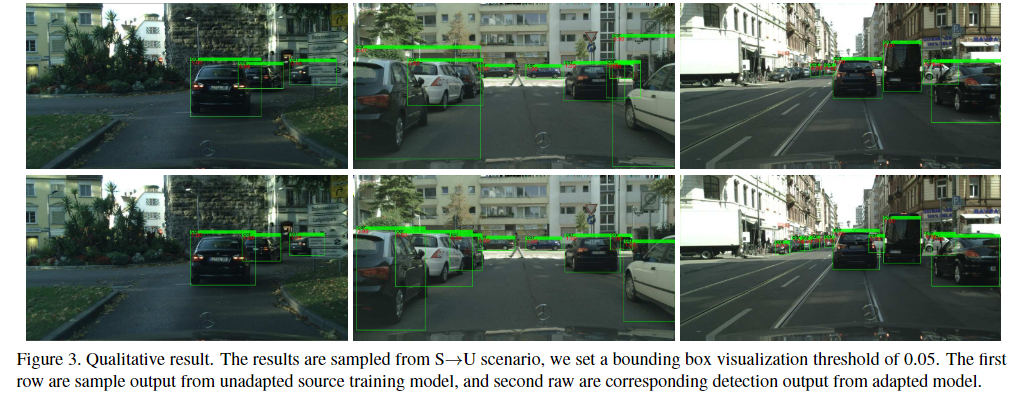
通过图片对比可以发现定位框更为紧凑在物体周围,对物体的识别更为精确,尤其是第3幅图与第6幅图,对远方细节不够明显的小车仍能够准确识别。
消融分析
说明:去掉原来的结构网络与加上该结构的网络所得到的结果进行对比。
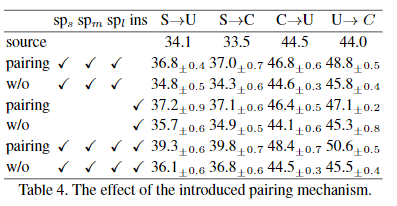
- 加入配对机制
- 框界对比
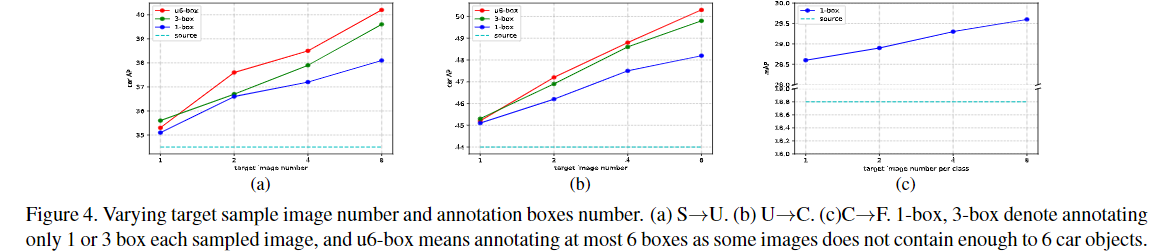
随着图像数量呈指数增长,大致线性的改进表明饱和效果。鉴别器之间的共享参数对于基于拆分池的自适应,我们使用相同的鉴别器结构,并在不同规模下使用共享参数。 尽管鉴别器也可以是独立的,而不是共享参数。
- 数据分析

-
精调直接导致非常大的方差,并且遭受严重的过度拟合,因此精调模型的性能要比源训练模型差。
-
强加SMFR可以大大减少方差,并且该模型实际上受益于有限的目标样本数据。 2)虽然SMFR不能改善拟议组件(例如sps,spm,spl,ins)的整体性能,但是可以大大减少差异。
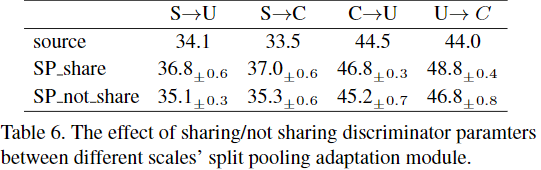
不同比例的部分对于图像级域偏移具有相似的表示特征。 它们是互补的,并且将它们组合进一步加强了鉴别器,从而产生了更好的域不变表示。
结论
在本文中,探索了仅利用少量目标域松散注释图像样本来缓解由于域移位而引起的目标检测器性能下降的可能性。 通过精心设计适配模块并施加适当的正则化,paper提供的框架可以在Faster R-CNN的基础上构建,可以以极少的目标样本将源训练的模型稳固地适应目标域,并且仍能胜过使用现有方法访问完整的未标记目标集的方法 。
代码复现
因为本文paper没有提供源码,所以这一步进展非常慢,持续更新。。。