计算机视觉解读
CV梗概
-
什么是计算机视觉?
-
首先不妨来看一下维基百科给的定义:
-
计算机视觉(Computer vision)是一门研究如何使机器“看”的科学,就是指用摄影机和计算机代替人眼对目标进行识别、跟踪和测量等机器视觉,并进一步做图像处理,用计算机处理成为更适合人眼观察或传送给仪器检测的图像。
-
计算机视觉研究相关的理论和技术,试图建立能够从图像或者多维数据中获取“信息”的人工智能系统。因为感知可以看作是从感官信号中提取信息,所以计算机视觉也可以看作是研究如何使人工系统从图像或多维数据中“感知”的科学。
- 这样理解可能相对比较抽象,简单说计算机视觉与图像有关,与人工智能技术有关,这也决定了自己在计算机视觉的方向选择会往哪个地方靠近。
CV热点领域
- 画面重建
- 事件监测
- 目标跟踪
- 机器学习
- 索引建立
- 图像恢复
- 实例分割
这里拿单独几个感兴趣的点来分析:
-
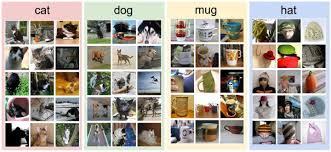
图像分类
- 给定一组各自被标记为单一类别的图像,我们对一组新的测试图像的类别进行预测,并测量预测的准确性结果,这就是图像分类问题。
- 实现步骤
- 输入是由 N 个图像组成的训练集,共有 K 个类别,每个图像都被标记为其中一个类别。
- 使用该训练集训练一个分类器,来学习每个类别的外部特征。
- 预测一组新图像的类标签,评估分类器的性能,用分类器预测的类别标签与其真实的类别标签进行比较。
- 目前较为流行的架构是卷积神经网络(CNN)
-
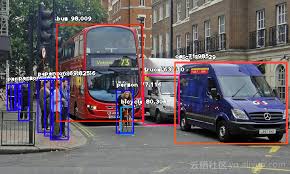
对象检测
- 对象检测通常会涉及到为各个对象输出边界框和标签。这不同于分类与定位(只对很多对象进行分类和定位),不仅仅是对个主体对象进行分类和定位。在对象检测中,你只有 2 个对象分类类别,即对象边界框和非对象边界框。
- 比较流行的是区域卷积神经网络(R-CNN),其实现步骤
- 在 R-CNN 中,使用选择性搜索算法扫描输入图像,寻找其中的可能对象,从而生成大约 2,000 个区域建议。
- 在这些区域建议上运行一个 卷积神网络。
- 将每个卷积神经网络的输出传给支持向量机( SVM )使用一个线性回归收紧对象的边界框。
- 改良的框架还有Faster R-CNN。
-
语义分割
- 将整个图像分成一个个像素组,然后对其进行标记和分类。特别地,语义分割试图在语义上理解图像中每个像素的角色(比如,识别目标物是太阳、星星还是其他的类别)。
- 目前采用的是全卷积神经网络(FCN)

如何学习CV
- 入门基础:冈萨雷斯数字图像处理(dip)+opencv+python/matlab+C++
像素级的图像处理知识是计算机视觉的底层基础知识。需要有基本的术语概念知识打底,否则遇到问题也没有思路,不知道如何搜索,这无法做较深入的研究,欲速则不达,所以先打好基础。

OpenCV契合python,可移植性强,运行速度比较快。MATLAB比较简单,而且之前参加数模时候用的也比较多,可以配合着使用,来回切换贯通。C++也是和opencv有很大的关联,一般来说需要用好C++。但不太好全部一起学,所以,供选择,具体情况具体分析。

- 进阶:机器学习+深度学习。
这个时候有了一定的图像处理基础,可以学习机器学习深度学习上的东西,推荐书籍周志华西瓜书、Computer Vision: Models, Learning, and Inference。